@Repository
public class MemberRepository {
@PersistenceContext
private EntityManager em;
}
@Repository - 컴포넌트 스캔으로 자동으로 스프링 빈 관리됨
@PersistenceContext - JPA 표준 애노테이션
private EntityManager em; - 스프링이 EntityManager를 만들어 주입해줌(Injection)
생성자 주입
@Repository //컴포넌트 스캔으로 자동으로 스프링 빈 관리됨
public class MemberRepository {
@Autowired
private EntityManager em; // 스프링이 엔티티메니저를 만들어 주입해줌 (Injection)
public MemberRepository(EntityManager em){
this.em = em;
}
}
스프링부트 라이브러리 사용 시 @PersistenceContext > @Autowired로 수정 가능
@Repository //컴포넌트 스캔으로 자동으로 스프링 빈 관리됨
@RequiredArgsConstructor
public class MemberRepository {
//@PersistenceContext // jpa 표준 애노테이션
private final EntityManager em; // 스프링이 엔티티메니저를 만들어 주입해줌 (Injection)
}
EntitiyManger는 @PersistenceContext 표준 어노태이션으로 주입해야 하나 스프링부트에서 @Autorwired도 Injection되도록 지원해줌
2) 편지를 배송하는 것과 같이 데이터 전송하여 목적지에 도착할 때까지 지켜야 하는 독립적인 여러 규칙을 거친다.
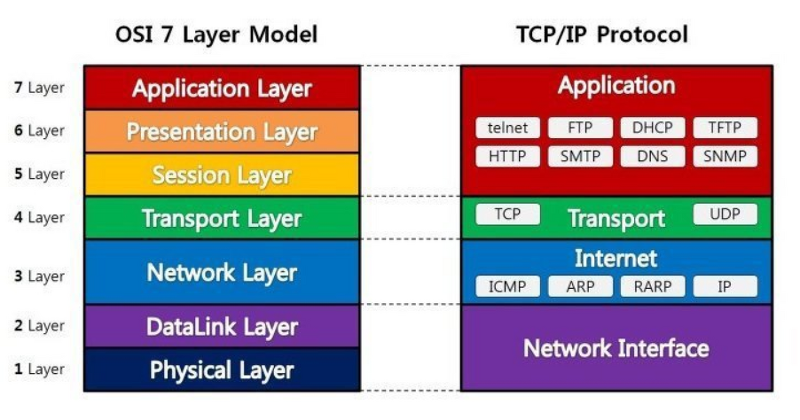
Lesson 07 OSI 모델과 TCP/IP 모델
1. OSI 모델이란?
1) 옛날에는 같은 회사 컴퓨터끼리만 통신이 가능했고 거기에 케이블을 연결하는 커넥터도 회사별로 다르다면 곤란했기 때문에 공통으로 사용할 수 있는 표준 규격을 정해야만 했다.
2) 표준 규격을 정하는 단체 중 ISO라는 국제표준화기구에서 OSI 모델이라는 표준 규격을 제정했다.
응용계층 : 이메일 및 파일 전송, 웹 사이트 조회 등 애플리케이션에 대한 서비스를 제공 표현 계층 : 문자코드, 압축, 암호화 등의 데이터를 변환 세션 계층 : 세선 체결, 통신 방식을 결정 전송 계층 : 신뢰할 수 있는 통신 구현 네트워크 계층 : 다른 네트워크와 통신하기 위한 경로 설정 및 논리 주소를 결정 데이터 링크 계층 : 네트워크 기기 간의 데이터 전송 및 물리 주소를 결정 물리 계층 : 시스템 간의 물리적인 연결과 전기 신호를 변환 및 제어
3) 송신 측은 데이터를 보내기 위해 상위 계층에서 하위 계층으로 데이터 전달. 각 계층은 독립적이므로 데이터 전달되는 동안 다른 계층의 영향을 받지 않는다.
4) 수신 측은 하위 계층에서 상위 계층으로 각 계층을 통해 전달된 데이터를 받는다.
2. TCP/IP 모델이란?
1) OSI 모델의 표현 계층, 세션 계층이 TCP/IP 모델에서는 응용 계층으로 포함
Lesson 08 캡슐화와 역캡슐화
1. 캡슐화와 역캡슐화란?
1) 데이터의 앞부분에 전송할 때 필요한 정보를 붙여서 다음 계층으로 보내야 하는데, 이 정보를 헤더라고 한다.
1-2) 헤더는 데이터를 전달받을 상대방에 대한 정보도 포함되어 있다.
2) 헤더를 붙여 나가는 것을 캡슐화라고 하는데 데이터 받는 족에서 헤더를 하나씩 제거하는 것을 역캡슐화라고 한다.
<송신 측 컴퓨터에서 웹 사이트에 접속하는 상황>
1. 응용 계층에서 웹 사이트를 접속하기 위한 요청 데이터 생성
2. 해당 데이터를 전송 계층으로 전달되는데 전송 계층에서 신뢰할 수 있는 통신이 이루어지도록 응용 계층에서 만들어진 데이터에 헤더를 붙인다. (캡슐화)
3. 전송 계층에서 만들어진 데이터를 다른 네트워크와 통신하기 위해 네트워크 계층에서 헤더를 붙인다.
4. 네트워크 계층에서 만들어진 데이터에 물리적인 통신 채널을 연결하기 위해 데이터 링크 계층에서 헤더와 트레일러를 붙인다.
4-1) 트레일러는 데이터를 전달할 때 데이터의 마지막에 추가하는 정보를 말함.
5) 데이터 링크 계층에서 만들어진 데이터는 최종적으로 전기 신호로 변환돼서 수신 측에 도착한다.
6) 수신 측에서는 각 계층의 헤더를 제거하면서 데이터를 전달하고 반대로 데이터 링크 계층부터 순서대로 상위 계층으로 전달
- 오토와이어와 컴포넌트 어노테이션을 활용해서 느슨한 결합으로 의존관계 주입 가능 - aop는 logging 등을 위해 메서드 호출 전후 나 메서드 리턴 후 등 활용 가능하고 비지니스 로직에 집중할 수 있도록 함 - 스프링은 스프링만의 orm을 제공하고 있지 않지만 하이버네이트나 아이바티스와 같은 Spring Integration을 제공한다. - 디스패처 서블릿, 모델앤뷰, 뷰 리졸버 등 개발을 도와 웹 애플리케이션 개발을 쉽게 만들어준다. - 스프링은 하이버네이트 데이터 소스나 엔티티 메니저, 세션, 트랙잭션을 관리하는 데 힘든 적이 있다. 그래서 환경 세팅을 할 때 시간을 너무 많이 소요하게 된다. - 스프링은 앞의 문제를 해결해준다. autoconfiguration를 사용하여 디펜더시를 구성함. - spring mvc, jackson databind, hibernate core, and log4j (for logging) 등을 사용할 때 잘 맞는 jars버전을 구성해야하는데 이때 부트는 spring boot starters를 사용해서 프로젝트를 쉽게 구성한다. - 만약에 스프링, 하이버네이트를 사용한다면 스타터에서 그냥 spring-boot-starter-data-jpa dependency를 추가하기만 하면 된다. - 스타터가 기본적으로 라이브러리를 추가해주기 때문에 우리는 디펜더시나 버전을 걱정할 필요가 없다.
고맙게도 동기가 보내준 블로그를 읽었는데 스프링 프레임워크의 특징적인 장점과 스프링 부트와의 차이점까지 알아볼 수 있었다. 스프링 강의에서 배웠던 내용이라서 복습 차 잘 읽었음!!
스프링 컨테이너과 함께 생성되고 종료될 때 유지가 되는데 스프링 빈은 싱글톤 스코프로 생성되기 때문.
<스프링의 다양한 스코프>
싱글톤: 기본 스코프, 스프링 컨테이너의 시작과 종료까지 유지되는 가장 넓은 범위의 스코프
프로토타입: 스프링 컨테이너는 프로토타입 빈의 생성과 의존관계 주입까지만 관여하고 더는 관리하지 않는 매우 짧은 범위의 스코프 (빈 생성, 의존관계 주입, 초기화 메서드 호출 뒤 클라이언트에 반환하고 관리하지 않음 즉 종료 메서드 호출이 안된다.)
웹 관련 스코프request: 웹 요청이 들어오고 나갈때 까지 유지되는 스코프
request: 웹 요청이 들어오고 나갈때 까지 유지되는 스코프
session: 웹 세션이 생성되고 종료될 때 까지 유지되는 스코프 (로그인 등)
application: 웹의 서블릿 컨텍스트와 같은 범위로 유지되는 스코프 (굉장히 긴 범위)
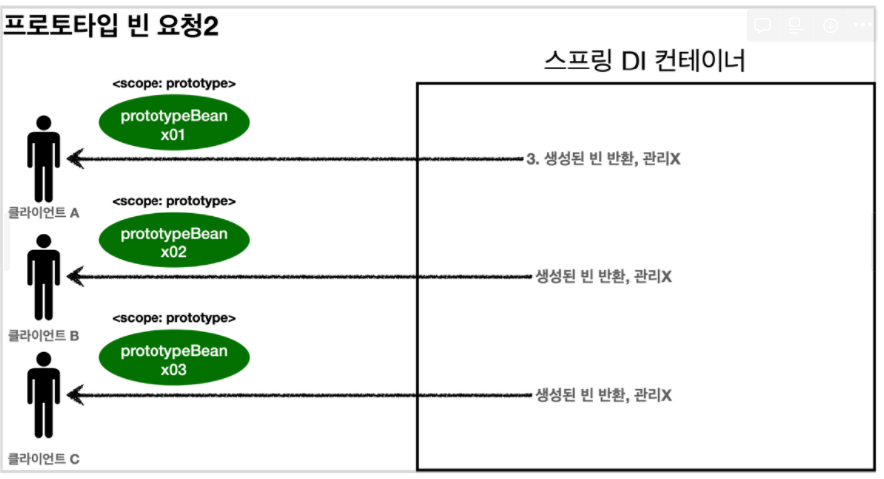
프로토타입 스코프
같은 인스턴스를 반환하는 싱글톤 스코프와 달리 프로토타입 스코프는 항상 새로운 인스턴스를 반환한다!
1. 프로토타입 스코프의 빈을 스프링 컨테이너에 요청한다. 2. 스프링 컨테이너는 이 시점에 프로토타입 빈을 생성하고, 필요한 의존관계를 주입한다. 3. 스프링 컨테이너는 생성한 프로토타입 빈을 클라이언트에 반환한다. 4. 이후에 스프링 컨테이너에 같은 요청이 오면 항상 새로운 프로토타입 빈을 생성해서 반환한다.
요청 시에 빈을 생성 후 반환하여 관리하지 않음
요청 → 빈 생성 / 의존관계 주입 → 반환 → 같은 요청 올 시 반복
정리
프로토타입 빈을 생성하고, 의존관계 주입, 초기화까지만 처리한다. 클라이언트에 빈을 반환하고, 이후 스프링 컨테이너는 생성된 프로토타입 빈을 관리하지 않는다. 프로토타입 빈을 관리할 책임은 프로토타입 빈을 받은 클라이언트에 있다. 그래서 @PreDestroy 같은 종료 메서드가 호출되지 않는다. (아예 호출 x)
대부분 싱글톤 스코프이고 어쩌다 프로토타입 스코프를 같이 쓰게 되는데 이때 문제가 발생하게 된다.
이 문제를 알아보자!
프로토타입 스코프 - 싱글톤 빈과 함께 사용시 문제점
스프링 컨테이너에 프로토타입 빈 직접 요청 시에는 정상적으로 요청 시에 빈을 생성하여 반환해줌
싱글톤에서 프로토타입 빈을 사용한다면 clientBean이 내부에 가지고 있는 프로토타입 빈은 주입이 된 상태이므로 클라이언트 A가 썼던 빈을 쓰게 된다.
package hello.core.lifecycle;
public class NetworkClient {
private String url;
public NetworkClient() {
System.out.println("생성자 호출 url = " + url);
connect();
call("초기화 연결 메시지");
}
public void setUrl(String url){
this.url = url;
}
//서비스 시작시 호출
public void connect(){
System.out.println("connect = " + url);
}
public void call(String message){
System.out.println("call = " + url + " message = " + message);
}
// 서비스 종료시 호출
public void disconnect(){
System.out.println("close = " + url);
}
}
실행 결과 > 객체 생성 후 외부에서 수정자 주입을 하기 때문에 null
생성자 호출, url = null
connect: null
call: null message = 초기화 연결 메시지
이와 같이 외부에서 값을 세팅 후 초기화 진행해야할 경우가 많음
스프링 빈 라이프사이클 객체 생성 → 의존관계 주입 (생성자 주입은 예외)
스프링은 의존관계 주입이 완료되면 스프링 빈에게 콜백 메서드를 통해서 초기화 시점을 알려주는 기능 제공
(싱글톤의 경우) 스프링 컨테이너가 종료되기 직전에 소멸 콜백 기능
[싱글톤] 스프링 빈의 이벤트 라이프사이클
스프링 컨테이너 생성 → 스프링 빈 생성(생성자 주입) → 의존관계 주입(setter, field injection) → 초기화 콜백 → 사용 → 소멸전 콜백 → 스프링 종료
초기화 콜백: 빈이 생성되고, 빈의 의존관계 주입이 완료된 후 호출
소멸전 콜백: 빈이 소멸되기 직전에 호출
참고: 객체의 생성(new해서 인스턴스 생성)과 초기화를 분리하자. 생성자는 필수 정보(파라미터)를 받고, 메모리를 할당해서 객체를 생성하는 책임을 가진다. 반면에 초기화는 이렇게 생성된 값들을 활용해서 외부 커넥션을 연결하는등 무거운 동작을 수행한다. 따라서 생성자 안에서 무거운 초기화 작업을 함께 하는 것 보다는 객체를 생성하는 부분과 초기화 하는 부분을 명확하게 나누는 것이 유지보수 관점에서 좋다. 물론 초기화 작업이 내부 값들만 약간 변경하는 정도로 단순한 경우에는 생성자에서 한번에 다 처리하는게 더 나을 수 있다.
따라서 객체를 생성하고 메모리에 등록하는 작업과 의존관계를 주입한 뒤, 커낵션을 연결하는 등의 객체의 동작인 초기화작업은 따로 분리. 즉, 생성자 안에서는 객체 내부에 값을 세팅하는 정도만 작업하고 이외에 무거운 수행 동작은 메소드를 분리하라!
객체 생성과 초기화를 분리했을 때의 장점 : 연결만 생성해두고 초기화 동작을 지연 > 실제 요청이 들어오면 초기화 진행할 수도 있음
참고: 싱글톤 빈들은 스프링 컨테이너가 종료될 때 싱글톤 빈들도 함께 종료되기 때문에 스프링 컨테이너가 종료되기 직전에 소멸전 콜백이 일어난다. 뒤에서 설명하겠지만 싱글톤 처럼 컨테이너의 시작과 종료까지 생존하는 빈도 있지만, 생명주기가 짧은 빈들도 있는데 이 빈들은 컨테이너와 무관하게 해당 빈이 종료되기 직전에 소멸전 콜백이 일어난다. 자세한 내용은 스코프에서 알아보겠다.
스프링 빈 생명주기 콜백 3가지 방법
인터페이스(InitializingBean, DisposableBean)
설정 정보에 초기화 메서드, 종료 메서드 지정
@PostConstruct, @PreDestroy 애노테이션 지원
하나씩 알아보자.
1. 인터페이스 InitializingBean, DisposableBean
public class NetworkClient implements InitializingBean, DisposableBean {
@Override
public void afterPropertiesSet() throws Exception {
//의존 관계 주입이 끝나면
System.out.println("NetworkClient.afterPropertiesSet");
connect();
call("초기화 연결 메시지");
}
@Override
public void destroy() throws Exception {
System.out.println("NetworkClient.destroy");
disconnect();
}
}
- InitializingBean
싱글톤 빈이라 컨테이너 올라올 때 빈이 생성이 되고 의존관계 주입이 다 끝나고 나면 호출이 됨
- DisposableBean
싱글톤 빈들이 죽을 때
생성자 호출 url = null
connect = <http://hello-spring.dev>
call = <http://hello-spring.dev> message = 초기화 연결 메시지
21:05:44.655 [main] DEBUG org.springframework.context.annotation.AnnotationConfigApplicationContext - Closing org.springframework.context.annotation.AnnotationConfigApplicationContext@4dbb42b7, started on Thu Oct 27 21:05:44 KST 2022
close = <http://hello-spring.dev>
초기화, 소멸 인터페이스 단점
이 인터페이스는 스프링 전용 인터페이스다. 해당 코드가 스프링 전용 인터페이스에 의존한다.
초기화, 소멸 메서드의 이름을 변경할 수 없다.
내가 코드를 고칠 수 없는 외부 라이브러리에 적용할 수 없다.
class 파일로 컴파일된 것을 받아서 maven이나 gradle로
초창기에 나온 방법들이라 지금은 잘 사용하지 않는다.
2. 빈 등록 초기화, 소멸 메서드 지정
public void init() {
//의존 관계 주입이 끝나면
System.out.println("NetworkClient.init");
connect();
call("초기화 연결 메시지");
}
public void close() {
System.out.println("NetworkClient.close");
disconnect();
}
@Configuration
static class LifeCycleConfig {
@Bean(initMethod = "init", destroyMethod = "close")
public NetworkClient networkClient() {
NetworkClient networkClient = new NetworkClient();
networkClient.setUrl("<http://hello-spring.dev>");
return networkClient;
}
}
설정 정보 사용 특징
메서드 이름을 자유롭게 줄 수 있다.
스프링 빈이 스프링 코드에 의존하지 않는다.
코드가 아니라 설정 정보를 사용하기 때문에 코드를 고칠 수 없는 외부 라이브러리에도 초기화, 종료 메서드를 적용 가능
종료 메서드 추론
@Bean의 destroyMethod 는 기본값이 (inferred) (추론)으로 등록되어 있다.
destroyMethod = “(inferred)”
이 추론 기능은 close , shutdown 라는 이름의 메서드를 추론해서 자동으로 호출 (라이브러리는 대부분 close , shutdown 이라는 이름의 종료 메서드를 사용)
직접 스프링 빈으로 등록하면 종료 메서드는 따로 적어주지 않아도 잘 동작한다.
추론 기능을 사용하기 싫으면 destroyMethod="" 처럼 빈 공백을 지정하면 된다.
AutoCloseable> 기본 메서드 이름이 close()로 되어있음
3. 애노테이션 @PostConstruct, @PreDestroy
import javax.annotation.PostConstruct; //javax 로 시작하면 자바 진영에서 공식적으로 지원함
import javax.annotation.PreDestroy;
public class NetworkClient {
@PostConstruct
public void init() {
//의존 관계 주입이 끝나면
System.out.println("NetworkClient.init");
connect();
call("초기화 연결 메시지");
}
@PreDestroy
public void close() {
System.out.println("NetworkClient.close");
disconnect();
}
}
static class LifeCycleConfig {
@Bean
public NetworkClient networkClient() {
NetworkClient networkClient = new NetworkClient();
networkClient.setUrl("<http://hello-spring.dev>");
return networkClient;
}
}
@PostConstruct, @PreDestroy 애노테이션 특징
최신 스프링에서 가장 권장하는 방법
애노테이션 하나만 붙이면 되므로 매우 편리
패키지 javax.annotation.PostConstruct : 스프링에 종속적인 기술이 아니라 JSR-250라는 자바 표준(인터페이스의 모음이라고 보면 된다.)이기 때문에 스프링이 아닌 다른 컨테이너에서도 동작
컴포넌트 스캔과 잘 어울린다.
NetworkClient 를 컴포넌트 스캔해도 어울림 (Config에서도 컴포넌트 스캔 필요하긴 함)
유일한 단점은 외부 라이브러리에는 적용하지 못함
외부 라이브러리를 초기화, 종료 해야 하면 @Bean의 기능을 사용하자.
정리
@PostConstruct, @PreDestroy 애노테이션을 사용하자
코드를 고칠 수 없는 외부 라이브러리를 초기화, 종료해야 하면 @Bean 의 initMethod , destroyMethod를 사용하자.